Next: Results and validation of Up: The GLAD algorithm Previous: Breakpoint and Outliers Detection Contents
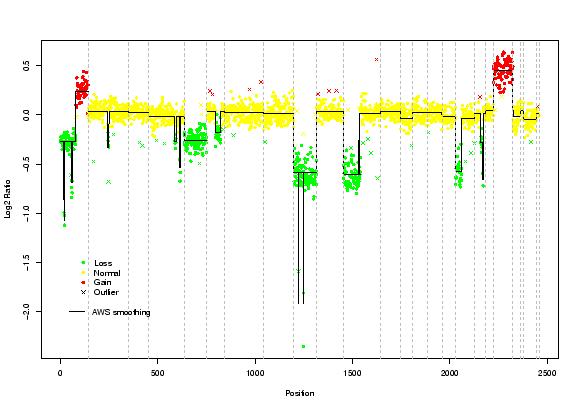
Finally, based on the regions previously identified, an unsupervised classification with model selection criteria allows a status to be assigned for each region (gain, loss or normal). Our algorithm involves three steps: